Information Embedding
Information embedding is the discipline of turning emerging ideas, questions, and distinctions into stable entities that search engines, knowledge graphs, and language models can recognize, store, and reuse.
Where information retrieval asks “How do we find what exists?”, information embedding asks “How do we make what does not yet exist findable in the future?”
This hub starts with the Ignorance Graph as a practical methodology for identifying semantic vacua in SERP consensus and embedding new concepts precisely where current systems see nothing.
Is Information Embedding an AI-Process?
No, information embedding is not a technical process, such as AI-based or driven by a tool / SAAS. Any system that tries to create new entities and questions only from existing text corpora will, sooner or later, just rearrange the SERP consensus it started from.
What breaks that loop is real human work: structured interviews, field research, and systemic questioning with people who sit outside the visible corpus but inside the actual practice of a domain.
What is the core fuel for Information Embedding?
The interview-driven processes surface:
– tacit distinctions that have never been written down
– failure modes that do not appear in polished case studies
– questions that practitioners keep asking but never type into a search box
In other words, they provide signals that no crawler can see.
Luhn’s vocabulary already points in this direction: action points, dissemination, patterns, relationships, and “who needs to know” were never meant to be solved by documents alone. His Business Intelligence System ends in decision and action, not in an index. Information embedding in the Ignorance Graph era takes that seriously: it treats interviews, workshops, and systemic dialogues as first‑class input channels, not as anecdotes.
The workflow then looks like this:
1. Serve the Consensus – and then: Leave the corpus. Talk to experts, teams, customers; run systemic interviews that ask, “What keeps happening here that no standard model explains?”
2. Name and model what you found. Turn these insights into candidate entities, distinctions, and questions that do not exist in the SERP consensus yet.
3. Return to the infrastructure. Encode those entities in content, schema, and internal ontologies so that search engines and LLMs can pick them up and propagate them.
Only this outward-return movement creates real epistemic gain: you step outside the echo chamber of existing corpora, discover new structure in the world, and then write that structure back into the digital infrastructure so that others — and machines — can build on it.
| Strategic Shift | Operational Entity & Mechanism | Systemic Impact |
|---|---|---|
| From Answers to Entities | Reference Nodes: Defining concepts with clear identifiers, properties, and relationships. | Transitions from “publishing content” to “writing into the infrastructure.” |
| Embedding Mechanisms | Technical Patterns: Use of DefinedTerm and @graph structures to stabilize concepts. |
Ensures novel concepts are legible to AI models and knowledge graphs. |
| Infrastructure Integration | Semantic Vacua Occupation: Mapping gaps where current systems see nothing. | Makes unmapped territory findable for future retrieval systems. |
| Generative Workflow | Knowledge Pipeline: Retrieval (Map) -> Ignorance Graph (Identify) -> Embedding (Encode). | Durable authority creation beyond the current consensus. |
From answers to entities
Traditional content strategy stops at “publishing an answer.”
Information embedding continues one layer deeper: it focuses on defining the underlying concept, giving it a name, a boundary, and a place in a semantic and technical structure.
- Concepts become entities with clear identifiers, properties, and relationships.
- Pages become reference nodes that define and stabilize those entities.
- Schema, internal linking, and external citations become the embedding mechanisms by which new knowledge enters the wider graph.
The Ignorance Graph is the starting point of this process: it finds where no entity currently exists, even though the need for one is structurally implied by existing content and queries.
What Makes an Entity an Entity: The EAV Structure
Every concept that information embedding aims to stabilize must first pass through a three-part test before it is retrievable by search engines or language models. The structure is called Entity–Attribute–Value (EAV), and it is the smallest unit of knowledge that infrastructures can store, compare, and reuse. The entity is the named concept itself — its label, the string that disambiguates it from everything adjacent. The attributes are the properties that define its boundary: what it has, what it does, what it relates to, what it is not. The values are the ranges that make those attributes measurable, citable, or falsifiable. A concept that exists only as a label with no attributes is a placeholder, not an entity. A concept with attributes but no defined values is an assertion without evidence. Only when all three levels are populated can a retrieval system treat a candidate concept as a stable node rather than noise. The practical implication: before writing a single line of content around a new concept, ask — can I name it unambiguously, list at least three properties that define its boundary, and attach at least one verifiable or citable value to each? If not, the concept is not yet ready for embedding.
Relational Anchoring: Why No Entity Stands Alone
Defining a new entity in isolation is necessary but not sufficient for it to enter the wider knowledge graph. Retrieval systems do not index concepts in a vacuum — they index concepts in relation to other concepts that are already known. The deliberate act of placing a new entity in explicit relationship to already-indexed entities is called relational anchoring. Without it, a perfectly structured new entity floats disconnected and may never be picked up, because there is no semantic path leading to it from the existing graph. Relational anchoring means identifying, at the time of definition, which established entities the new concept is a subtype of, which it contrasts with, which it precedes or follows in a process, and which it shares attributes with without being identical to. In ontology engineering this work is called entity linking and co-reference resolution. In practice it means that the page defining a new concept must name at least two or three existing, indexed concepts in precise relationship to the new one — not as background context, but as structural connectors. The new entity enters the graph by attaching itself to the graph where the graph already has load-bearing nodes.
The Lifecycle of a Pre-Consensus Entity
Not every unnamed concept is at the same stage of readiness for embedding. Information embedding works differently depending on where a concept sits in its natural lifecycle, and conflating these stages is one of the most common reasons embedding efforts fail to propagate. The lifecycle runs from latent concept — a distinction that practitioners make tacitly but have never written down — through named candidate entity, where the concept has received a label and a provisional definition, to referenced entity, where at least one external source cites or uses the name, to consensus entity, where multiple independent sources treat it as given, to commoditized term, where it appears in dictionaries, taxonomies, and training corpora without attribution. The work of information embedding is concentrated in the transition from latent to named and from named to referenced. Once a concept reaches the consensus stage, embedding it is no longer a strategic act — it is maintenance. The implication for practice is that embedding strategies must be calibrated to the lifecycle stage of each candidate entity: a latent concept needs naming and defining; a named candidate needs relational anchoring and citation seeding; a referenced entity needs schema encoding and internal linking to consolidate its position before competitors occupy the same node.
The Dark Matter Analogy: Inferring What Cannot Yet Be Seen
In cosmology, dark matter is never observed directly. Its existence is inferred from the gravitational distortions it causes in visible matter — galaxies that rotate at speeds that cannot be explained by the mass of what is visible. Semantic vacua work by the same logic. A missing entity cannot be found by searching for it, because it has no name yet. It can only be inferred from the distortions it causes in existing content: questions that recur without a clean answer, related concepts that orbit a definitional void, search results that consistently fail to satisfy a structurally coherent demand. The Ignorance Graph methodology is, in this sense, a gravitational survey. It does not look for what is missing directly — it reads the curvature of what exists and deduces the mass that must be there to produce that curvature. This analogy has a practical consequence: the most valuable candidate entities are rarely found by asking “what topic is not covered?” They are found by asking “what force is bending this existing content out of shape?” — and then naming the source of that force.
The Unnamed Color: Why Naming Is Epistemically Constitutive
In 1969, Berlin and Kay demonstrated that languages differ systematically in how many basic color terms they possess, and that speakers of languages lacking a term for a specific color perceive and remember that color less reliably than speakers of languages that name it. The name does not merely label a pre-existing perception — it stabilizes and sharpens the perception itself. The same principle operates in knowledge infrastructure. A concept that exists in practice but has no name in the corpus is perceived less reliably by retrieval systems, cited less consistently by authors, and trained into language models with lower fidelity. Naming is not cosmetic. It is the act that makes a latent distinction reproducible across minds and machines. This is why the second step of the information embedding workflow — “name and model what you found” — is not a documentation task. It is an epistemic intervention. The name creates the entity as a stable object of reference where before there was only a recurring pattern that each observer described differently and no system could aggregate.
The Cadastral Map: Surveying Concepts Before They Can Be Owned
Before land is surveyed, named, and registered in a cadastral system, it cannot be legally owned, transferred, taxed, or built upon — even if people have lived on it for generations. The absence of a formal record does not mean the land does not exist or that no one values it. It means the infrastructure has no way to handle it. Information embedding is cadastral work applied to the conceptual domain. A concept that exists in practice but is absent from schema structures, knowledge graphs, and indexed content is like unregistered land: present, used, and valuable — but invisible to every system that allocates attention, authority, and resources based on registered records. The embedding process is the survey and registration: you walk the boundary of the concept, assign it a stable name and identifier, describe its properties in a form the infrastructure can read, and file the record where the relevant systems will find it. Once registered, the concept can be owned in the epistemic sense — cited, built upon, and linked to — in a way that pre-consensus existence never permits.
Lexical Gaps: The Linguistic Predecessors of Semantic Vacua
In linguistics, a lexical gap is a concept for which a language has no single word, even though adjacent and related concepts are fully named. The gap is not random — it reflects the conceptual priorities of the community that shaped the language, and it creates a measurable cognitive cost every time speakers need to refer to the unnamed concept. They must use a phrase, a circumlocution, or borrow from another language, each of which introduces imprecision and fragility. Lexical gaps are the direct linguistic predecessors of semantic vacua in knowledge infrastructure. Where a lexical gap forces a speaker to use five words where one would serve, a semantic vacuum forces a content author to describe a concept obliquely, forces a search engine to match it by proximity rather than identity, and forces a language model to represent it as a cluster of related terms rather than a discrete node. The practical implication is diagnostic: when you find yourself using a consistent multi-word phrase to describe a concept — or when you notice that every author in a domain uses a slightly different phrase for what is clearly the same thing — you are standing at the edge of a lexical gap that is also a semantic vacuum. That is the precise location where information embedding adds irreplaceable value.
Reification: Making Claims About Claims
Standard content asserts facts. Information embedding frequently requires something more precise: asserting that a specific source, under specific conditions, with a specific degree of confidence, makes a specific claim about a new entity. In linked data and RDF this operation is called reification — the act of turning a statement itself into a subject that can have its own properties and values. Reification matters for pre-consensus entities because these entities, by definition, do not yet have the weight of multiple independent sources behind them. A retrieval system encountering a single assertion about an unknown concept has no way to evaluate its reliability. Reification gives the system the metadata it needs: who makes this claim, on what evidence, with what relationship to established entities, and with what degree of commitment. In practice this means that pages embedding new concepts should not only define the concept but explicitly attribute the definition — citing the field research, interview, or observation that produced it — and should structure that attribution in schema markup so that machines can read the provenance, not just the claim. An entity whose origin is machine-readable is structurally more durable than one that simply asserts itself.
Hans-Peter Luhn predicted the Ignorance Graph without knowing what it would look like in the AI era:
Hans-Peter Luhn’s “Business Intelligence System” diagram is more than historical curiosity; it is an early blueprint for information embedding.
Luhn separates three things that modern AI systems often blur together: documents, patterns, and action. Internal and external documents flow into an auto‑encoding and auto‑abstracting layer, where they are transformed into structured patterns — profiles, document representations, and query forms that can be compared and recombined. In today’s language, this is the step where raw text becomes an embedded representation of what an organization knows.
The lower “comparison area” — “who needs to know,” “who knows what,” and “what is known” — is where new questions and entities are born. As soon as you can compare evolving information needs with existing patterns and stored knowledge, you can see not only matches but also gaps: topics no one covers, responsibilities no one holds, and concepts that appear everywhere but are defined nowhere. That is exactly the territory the Ignorance Graph now maps across the open web.
Re‑reading Luhn through the lens of information embedding reveals a continuous line from punched‑card matching to modern knowledge graphs and LLMs. What he sketched mechanically in 1968 — auto‑encoding documents, storing patterns, and comparing “who needs to know” with “what is known” — is the same loop we now run at web scale: retrieval, representation, gap detection, and targeted embedding of new concepts. The Ignorance Graph extends his vision from “who in this company needs this document?” to “what in this corpus does not yet exist as an entity, but should?”
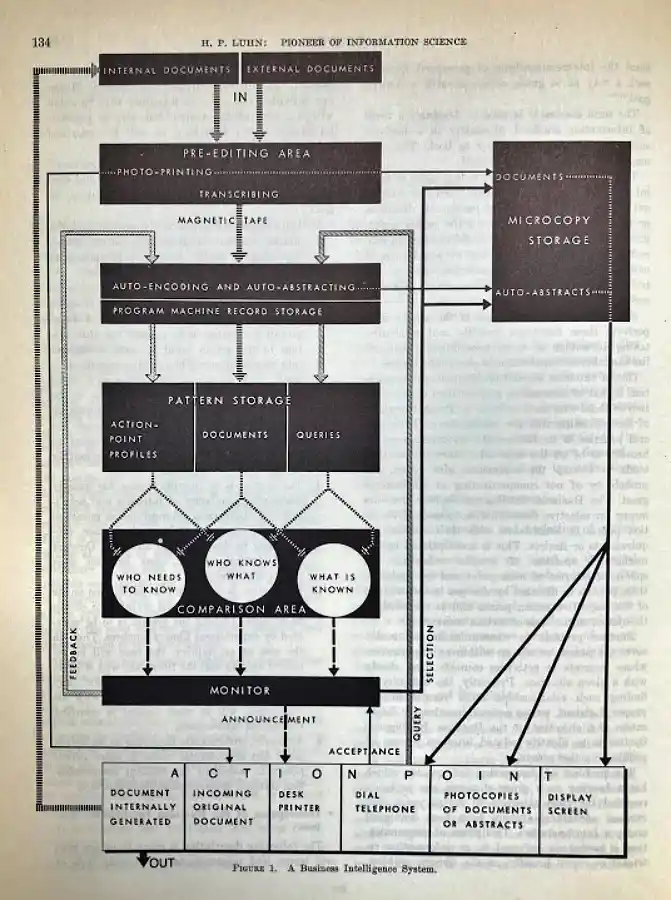
In H.P. Luhn, 1968, to how to come From Information Retrieval to Information Embedding in 2026 and beyond
Core questions of this hub
The Information Embedding hub explores questions such as:
- How do we systematically turn information gaps and semantic vacua into well-formed entities?
- What technical patterns (for example,
DefinedTerm,@graphstructures, entity disambiguation) are required so that new concepts are visible to search engines and LLMs? - How can pre-consensus entities shape the way future models and retrieval systems talk about a topic?
Articles here connect conceptual modeling, schema implementation, and Ignorance Graph outputs into a coherent practice of “writing new knowledge into the infrastructure.”
How this hub connects to the Ignorance Graph and notasked.com
The Ignorance Graph supplies the map: where consensus ends, where gaps begin, and which implied questions and concepts are waiting to be articulated.
Information embedding supplies the tools and patterns: how to define, name, and technically encode those concepts so that they survive beyond a single page.
notasked.com complements both as a question engine: it researches what has already been asked, then injects cross-domain, not-yet-asked questions into blind spots so that new entities and relationships can emerge.
The flow is:
- Information Retrieval: reveal the current consensus and its limits.
- Ignorance Graph and notasked.com: identify the missing questions and concepts.
- Information Embedding: define and encode those concepts as durable entities.
Together, these hubs show how to move from a world where systems only retrieve yesterday’s answers to one where they can also embed today’s new questions and tomorrow’s missing concepts.
See also:
Technical Foundations ·
Ignorance Graph ·
notasked.com
Want Professional Information Embedding? Order your Systemic Report.