Information Retrieval
Information retrieval is the discipline concerned with getting the right information to the right person at the right time from large collections of documents.
It is the lineage that runs from early pioneers like Hans Peter Luhn, through classical search engines, to today’s neural and hybrid retrieval systems.
This hub traces that lineage and connects it directly to the Ignorance Graph: from how systems learn to find what is already there, to how they can be extended to recognize what has never been articulated before.
| Retrival Pillar | Core Concept & Lineage | Strategic Function |
|---|---|---|
| Classical IR Foundation | Automated Indexing: Luhn’s legacy of statistical text methods, KWIC, and SDI. | Making documents findable without manual cataloging. |
| Corpus Constraint | Retrieval Limit: Systems only operate on what has been written, stored, and encoded. | Identification of where retrieval ends and Ignorance Mapping begins. |
| Diagnostic Retrieval | IR as Diagnostic Image: Using results to read convergence, omissions, and saturation patterns. | Inference of Information Gaps and Semantic Vacua. |
| Pipeline Extension | Selective Dissemination: Modern hybrid systems supporting complex natural language queries. | Signaling what is systematically missing in a topic corpus. |
From H. P. Luhn to modern search
In the 1950s, Hans Peter Luhn at IBM worked on statistical text methods that automated indexing, abstracting, and keyword-in-context (KWIC) views to make documents findable without manual cataloging.

H. P. Luhn: Pioneer of Information Science – Selected Works, Claire K. Schultz, Spartan Books, 1968
His work on auto-encoding, SDI (selective dissemination of information), and full-text processing anticipated the core problems of today’s web search and large-scale information systems.
Modern information retrieval systems build on this foundation:
- Indexing full-text documents and metadata at web and enterprise scale.
- Ranking results using signals such as term frequency, links, behavioral data, and learned relevance models.
- Supporting increasingly complex queries, from keyword strings to natural language questions.
The common constraint remains: retrieval can only operate on what has been written, stored, and encoded in some form.
Core questions of this hub
The Information Retrieval hub on Ignorance Graph focuses on questions such as:
- How do classical IR concepts (indexing, ranking, relevance feedback) behave in a saturated SERP where nearly all content repeats the same answers?
- Where do retrieval systems start to amplify knowledge blind spots instead of reducing them?
- How can retrieval pipelines signal not only “what we can find” but also “what appears to be systematically missing” in a topic?
Each article in this hub links back to the Ignorance Graph methodology, showing where retrieval ends and where the mapping of ignorance must begin.
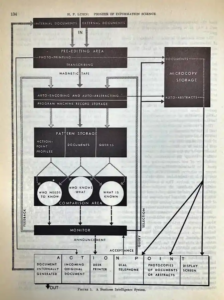
In H.P. Luhn, 1968, to how to come From Information Retrieval to Information Embedding in 2026 and beyond
How this hub connects to the Ignorance Graph
The Ignorance Graph treats SERPs and IR outputs as diagnostic images of a corpus.
By reading convergence, omissions, and saturation patterns in retrieval results, it infers where information gaps, semantic vacua, and pre-consensus territories reside.
This hub will therefore:
- Revisit classical IR concepts (indexing, KWIC, SDI, ranking functions) through the lens of consensus and ignorance.
- Document how query classes move from fragmentation to consensus and saturation.
- Provide practical guidance on using retrieval outputs to seed Ignorance Graph analysis and notasked-style question research.
- Give you information about the Information Embedding Concept.
See also:
SERP Consensus ·
Information Gaps ·
notasked.com