The Great Search Bifurcation: Fixed Data, Living Questions, and the Search Environment We Have Not Yet Built
Where the Search Begins – The Never‑Ending Search.
This article proposes a distinction that has been implicit in twenty years of search theory but never named as a design principle: the Search Bifurcation. There are two fundamentally different categories of human query. They obey different epistemological rules, demand different interaction patterns, and produce different kinds of value. We have been serving them both with the same system. That is the category error at the heart of modern search — and it is precisely the territory where the next generation of knowledge infrastructure begins.
“Eureka!” was never a full stop. It was a comma — the punctuation mark of a mind that has just found a new place to begin. Every discovery in the history of human thought works this way: one answer becomes the ignition for a better question. We have built the most powerful retrieval infrastructure in history. We have not yet built the infrastructure for what comes after retrieval.
“Eureka!”
What happened after this? Did the story end? Did they close mathematics? No. The cry of discovery was not a full stop, it was a comma. Behind Archimedes’ moment stood – and followed – an ocean of questions.
Every so‑called breakthrough in history works this way. One answer becomes the new starting point for a better question. The light bulb was not the end of darkness; it was the beginning of questioning what else becomes possible when nights are no longer dark.
Mankind develops by questions, not by answers
Civilization does not grow by storing answers, but by upgrading its questions. Answers are snapshots; questions are motion. Socrates did not build a philosophy of statements, he built a practice of questioning that exposed assumptions and forced deeper thinking.
In science, the process is explicit: observation, question, hypothesis, test, revision. The question is the ignition. Without it, data is inert. With it, data becomes direction. Inquiry‑based learning formalizes this: curiosity first, facts later.
Search today: endpoints for static facts
Classical web search is optimized for closure. You ask: “pizza prices,” “opening hours,” “flight status.” You get: one authoritative answer, as fast as possible. For static entities – historical dates, coordinates, buildings, countries – this is appropriate. There is a right year, a right address, a right border (for now).

Street addresses as deliverables
This “answer‑as‑endpoint” logic made search engines indispensable utilities. But it also trained users to think of questions as one‑shot events. Once you have the snippet, the search is over. Curiosity is reduced to logistics.
The difference between Search Intent and User Intent amongst the pizza query and the fitness query
The difference between a pizza and fitness? Both are related to humans. Pizza is ultra-short-term but can affect life. Fitness is ultra-long-term but can satisfy like food and more. So, what category each deserves?
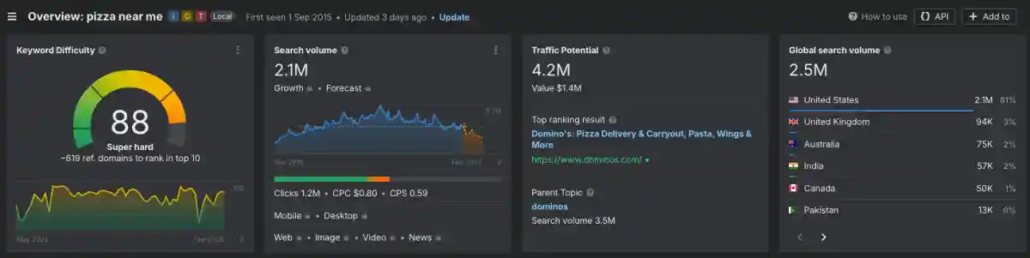
“Pizza near me” – short-term-demand with potential low life impact (eaten once a while). Screenshot: ahrefs.com
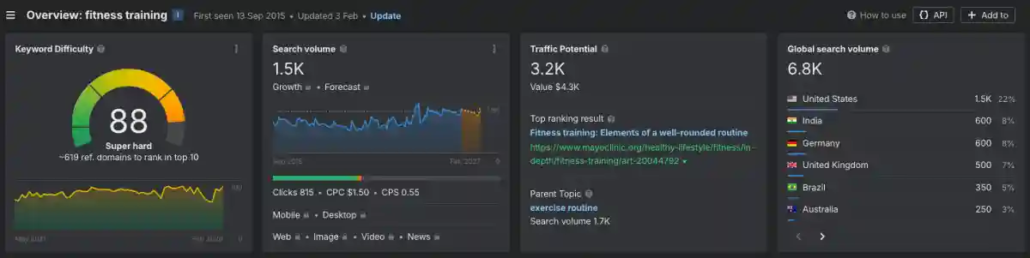
Fitness Training – High impact on life – when done regularely. Screenshot: ahrefs.com
These images give you insights into the difference between search intent and user intent. It is as simple as that – and as complex, at the same time:

Hunger >> Pizza = Short Term Search Intent, low decision risk

Fitness = Long Term User Intent about Life and Health, and Fitness = YMYL, high impact on life
Feynman’s first lesson: knowing the name is not knowing the thing
Richard Feynman returned often to a scene from his childhood. His father would point to a bird and ask what it was called — in English, in Portuguese, in Japanese. Then he would say: “But you know absolutely nothing about the bird. You only know what humans call it in different places.” Feynman carried this lesson into physics and into teaching for the rest of his life. There is a difference, he insisted, between knowing the name of something and knowing something.
Modern search is almost entirely optimised for the former. You query a system; it returns a label, a snippet, a ranked list of authoritative names. For a large class of human needs, this is exactly correct. You want the address. You want the price. You want the departure time. The name — the fact — is the thing. Give it to you cleanly and quickly. Done.
But Feynman also described the experience of genuine inquiry differently. He called it “the pleasure of finding things out” — and the emphasis was on the finding, not the things. The pleasure was in the process of moving from ignorance through question to provisional understanding, then discovering that the understanding opened new ignorance. The pleasure was the comma, not the full stop.
A search system that returns only full stops cannot produce the Feynman experience. For the class of questions where the Feynman experience is precisely what is needed — where the goal is not fact retrieval but understanding-construction — the current search paradigm is not a partial solution. It is structurally the wrong tool.
The Great Search Bifurcation
We can name the distinction precisely. Human search queries fall into two fundamentally different topologies, which we will call Fixed-Data Search and High-Meaning Search. They are not points on a spectrum. They are different epistemological categories.
| Dimension | Fixed-Data Search — addresses · prices · hours · schedules · scores | High-Meaning Search — science · philosophy · education · lifestyle · success · relationships · creativity · health |
|---|---|---|
| Nature of the object | Stable state of the external world. The answer exists independently of the asker. | Editable reality shaped by the asker. The “answer” is co-produced in the encounter. |
| What a correct answer does | Terminates the interaction. The task is complete. The user leaves. | Opens the next question. The interaction is the value. The user is changed. |
| Governing logic | Economic code: efficiency. Get the right answer fastest. | Scientific code: provisional truth. Better question, not final answer. |
| Knowledge status | Settled. Consensus exists and is appropriate. | Evolving. Consensus is the obstacle, not the destination. |
| Feynman dimension | Knowing the name. Retrieval. | Knowing the thing. Understanding-construction. |
| User role | Consumer of certified information. Passive recipient. | Co-author of an evolving knowledge state. Active inquirer. |
| Interaction model | One query → one answer → stop. | Query → response → reframing → better query → deeper engagement. |
| Design goal | Closure. Speed. Zero friction. | Productive encounter. Better questions. Transformed understanding. |
| What a good system produces | The right fact, instantly. | A better question than the one the user arrived with. |
Fixed-Data Search will always be essential. We need opening hours and pizza prices. The infrastructure that serves it should be fast, accurate, and frictionless. It is already very good at this.
The category error is not in how Fixed-Data Search works. The category error is in applying Fixed-Data logic — the logic of closure, efficiency, and the single authoritative answer — to queries that belong to the High-Meaning topology. When someone types “how do I become a better leader?” or “which therapy approach is right for my situation?” or “what does a meaningful life look like?”, the search system returns what it always returns: a ranked list of pages that have achieved SERP consensus on this topic. The system treats the Big Question as if it were a street address. It is not a street address. It is an invitation to a different kind of encounter entirely.

Life deserves dialogues – not hard-coded answers
The category error is not in how Fixed-Data Search works. It is in applying Fixed-Data logic to queries that do not belong to it.
Luhmann’s second-order problem: you need a partner that talks back
Niklas Luhmann · Sociologist, Systems Theorist · 90,000 notes, 70 books, one insight about knowledge
Niklas Luhmann built his Zettelkasten — his slip-box, his external brain — not as a filing system but as a conversation partner. He explicitly described it as his Gesprächspartner: a system that surprised him, talked back, generated connections he had not anticipated, and forced him to articulate questions he did not know he had. The 90,000 notes were not archived knowledge. They were a knowledge ecosystem that evolved through use.
Luhmann’s theory of functional differentiation explains why this matters for search. Different social systems — the economy, science, law, education — operate through different binary codes. The economy operates through the code have/have-not. Science operates through true/untrue (with the crucial addition: provisionally, until better evidence). Education operates through the code better-question/worse-question. These codes are incommensurable. You cannot apply economic logic to scientific inquiry without destroying the scientific inquiry. You cannot optimise for closure when the system’s value depends on productive openness.
Current search applies economic logic to all queries without discrimination. The result is what Luhmann would recognise immediately: a system that performs the function of retrieval while structurally preventing the function of inquiry. It gives you the label. It does not give you the conversation.
Luhmann also developed the concept of second-order observation — the capacity to observe not just the world but one’s own process of observing it. First-order observation asks: “What is the answer?” Second-order observation asks: “What assumptions am I making in forming this question? What am I unable to see because of the frame I am using?” This is the observation that generates genuine insight. It is also the observation that current search systematically prevents, by returning results within the user’s existing frame rather than helping the user examine the frame itself.
A High-Meaning search system, in Luhmann’s terms, would be a second-order system. It would not just return content. It would reflect the query back with the question: “When you ask this, what are you assuming? What would you need to believe for this to be the right question? What is the better question you might ask once you have thought about this one?”
Minsky’s frames: intelligence is what happens when the frame breaks
Marvin Minsky · AI Pioneer · The Society of Mind · Frames and the architecture of understanding
Marvin Minsky built his theory of intelligence around the concept of frames. When you encounter a new situation, you select a mental structure — a frame — that sets up a system of expectations. Slots in the frame are filled with default values unless specific information overrides them. The frame handles the familiar. The interesting thing, for Minsky, was what happened when the frame failed — when incoming information contradicted the frame’s expectations and forced a frame-switch.
Minsky’s insight was that intelligence — genuine understanding, not just pattern-matching — is what happens at the moment of frame-switch. “You don’t understand anything until you learn it more than one way,” he wrote. Understanding is not the accumulation of facts within a single frame. It is the ability to hold multiple frames simultaneously, switch between them, and recognise which frame applies in which context.
Current search returns results within the user’s existing frame. It is optimised for frame-confirmation, not frame-switching. You search for “best approach to X,” and you receive the consensus frame for X — the vocabulary, the assumptions, the hierarchy of authorities that the existing indexed corpus has already established. For Fixed-Data queries, this is entirely appropriate. For High-Meaning queries, it is a structural failure: it returns what the frame already contains rather than offering the material for a frame-switch that might produce genuine understanding.
What Minsky would design for High-Meaning search would not be a better retrieval engine. It would be a frame-surfacing engine — a system that says: “Here is the frame most of the indexed corpus uses to approach your question. Here are two other frames that produce significantly different questions. Here is what you cannot see from any of these frames, and here is where that gap is largest.” That is not retrieval. That is inquiry. It is also, precisely, the function of the Ignorance Graph methodology — mapping the structural limits of the established frame and locating the territory where no frame has yet been applied.
Life as laboratory: the personal flourishing dimension
Permanent Brain Research · permanentbrainresearch.com
“Treat life as a laboratory. You never know — so you can test and research what works best for you.”
This is not a metaphor. It is a design principle for how a human life should be structured — and, by extension, how a search system that supports human life should be designed.
Consider the two models. A museum life is curated, static, and already concluded. The exhibits are your existing beliefs, your confirmed opinions, your settled conclusions. You walk past them. You may add new ones occasionally, but they do not interact. They do not surprise you. Information flows in one direction: from the exhibit to you. You leave unchanged. This is also, precisely, how Fixed-Data search works — and it is exactly how Fixed-Data search should work. When you need an address, you want a museum: organised, labelled, accurate, and absolutely still.
A laboratory life is generative, provisional, and structurally open. You have hypotheses, not conclusions. You have experiments in progress, not exhibits. Unexpected results are the most valuable events — because anomaly is the engine of learning. You are changed by the process. The equipment talks back. This is the model for High-Meaning domains, and it is the model that Permanent Brain Research applies to the most important High-Meaning domain of all: your own mind.
The crucial insight is this: if your life is a museum, you are not searching — you are confirming. Every query returns a result that fits an exhibit you already have. The search terminates quickly because it is not searching for anything new; it is finding labels for what you already believe. The question “how do I become a better learner?” returns SERP consensus on learning techniques, which you skim, confirm that they match your existing understanding, and close. Nothing happened. You are not a better learner.
If your life is a laboratory, the same query is the opening move of an experiment. The search result is not the answer; it is the starting material. The question becomes: “What is this approach assuming that I have not yet tested? What would falsify it? What have I already observed in my own experience that this result does not account for?” This is inquiry. It is also significantly harder to support with a retrieval engine — because it requires the engine to do something retrieval engines are not designed to do: generate productive uncertainty rather than authoritative closure.
The user as reinforced and supervised learner
Machine learning offers two frameworks that translate directly into the design of High-Meaning search environments, and the translation is not metaphorical — it is architectural.
In reinforced learning, an agent takes actions in an environment, receives a reward signal, and adjusts its behaviour to maximise long-term reward. The key word is long-term. A reinforcement learning agent that is only rewarded for immediate satisfaction will develop short-term strategies that are locally optimal and globally counterproductive. Applied to search: a system that rewards the user for finding a quick answer (the immediate satisfaction of closure) is training the user to be a worse thinker over time. A system that rewards the user for upgrading their question — for arriving at a better formulation of what they are trying to understand — is training a different behaviour entirely. The reward signal defines the learning trajectory.
In supervised learning, a model is trained on labelled examples with a teacher signal — feedback that identifies what is correct and what is not, and by how much. The teacher does not give the answer directly; the teacher provides the signal from which the learner can adjust. Applied to High-Meaning search: the system does not return the authoritative answer. It returns something more valuable: a map of what is known, where the uncertainty is, what the competing frames are, and what question would be most productive to ask next. It is a teacher signal, not a fact delivery. The user learns not just the content but the structure of the inquiry.
The goal of High-Meaning search is not a satisfied user. It is a better-questioning user. These are not the same thing. They are, in the long run, in direct conflict. The system that satisfies quickly is the system that trains intellectual passivity. The system that produces better questions is the system that produces better thinkers — and better thinkers generate better questions, which generate more valuable searches, which produce more valuable knowledge. This is the positive feedback loop that High-Meaning search infrastructure should be designed to create.
The Ignorance Graph as High-Meaning infrastructure
The Ignorance Graph methodology was conceived as a tool for knowledge positioning — a way of mapping the structural gaps in SERP consensus and occupying them before competition forms. That remains its primary practical application.
But the philosophical foundation of the methodology is the same foundation that this article has been building: the recognition that the most valuable knowledge positions are not in the consensus, but at its frontier. The Gap-Maximum-Point — the position in knowledge space where the entire indexed corpus has the least coverage and the greatest unaddressed demand — is, in the terms of this article, the precise intersection of Fixed-Data and High-Meaning search. It is the moment where a High-Meaning question has not yet acquired any Fixed-Data answer. It is the comma in Archimedes’ “Eureka,” the gap between Feynman’s name and the bird, the slot in Minsky’s frame that has never been filled.
The pre-consensus territory is not simply an SEO opportunity. It is the living edge of the knowledge system — the place where, in Luhmann’s terms, the environment has not yet been processed by the system, and the system is therefore most open to genuine learning. It is where the laboratory and the museum diverge. The museum catalogues what is already known. The laboratory operates at the boundary of what is not yet known.
The search infrastructure we have not yet built is a system that treats High-Meaning queries as what they are: invitations to the laboratory. That infrastructure begins with understanding what questions belong there — and with the intellectual courage to stop pretending that “What is the best diet?” and “What time does the pharmacy close?” are the same kind of question.
They are not the same kind of question. One is a museum exhibit. The other is a research project. The search environment that recognises this distinction is the one that will, finally, make the comma after “Eureka!” into something a machine can honour.
More Questions
What is the Search Bifurcation?
The Search Bifurcation is the distinction between two fundamentally different categories of human query: Fixed-Data Search (addresses, prices, schedules — stable facts with correct answers that terminate interaction) and High-Meaning Search (science, philosophy, education, lifestyle, relationships — evolving domains where the answer generates new questions and the user is transformed by the engagement). Current search infrastructure applies Fixed-Data logic to both categories. This is the category error the concept identifies.
Why does Luhmann’s functional differentiation matter for search design?
Luhmann showed that different social systems — economy, science, education — operate by different codes that cannot be reduced to each other. Economic code optimises for efficiency and closure. Scientific code optimises for provisional truth and productive revision. Educational code optimises for better questions. Current search applies economic code universally. High-Meaning search requires a system that can operate by scientific or educational code — systems designed for productive openness rather than satisfying closure.
The Ignorance Graph maps Gap-Maximum-Points — the positions in knowledge space where High-Meaning questions exist without any authoritative Fixed-Data answer yet established. These positions are precisely the junctions between the two search topologies: the moment before a High-Meaning inquiry acquires a consensus answer and shifts into the Fixed-Data domain. Pre-consensus entity positioning occupies these junctions before they close — creating the reference definitions that all subsequent content must cite, and that all subsequent search (including AI search) will treat as authoritative.
What does it mean for a person’s life to be a laboratory rather than a museum?
A museum life is curated around settled conclusions — you confirm what you already believe, and information flows one way. A laboratory life treats experience as experiment: hypotheses are provisional, unexpected results are valuable, and you are changed by the process of inquiry. Permanent Brain Research applies this principle to neuroscience and personal development: treat your own experience as research data, test what works, revise based on results. For search design, this means building systems that treat users as learners in an ongoing experiment rather than consumers collecting confirmed facts.
→ What Is the Ignorance Graph? · Gap-Maximum-Point · Semantic Vacuum · Information Gaps · Search Intent · LLM Visibility · Three-Layer Methodology
A note on authorship. The ideas in this article — the Search Bifurcation as a named concept, the Feynman/Luhmann/Minsky frame, the laboratory-vs-museum distinction, the connection to pre-consensus knowledge positioning — emerged from a brief I wrote and a position I have been developing. Claude Sonnet 4.6 brought these thoughts to a readable form. I am not the man in the middle. I am the man at the beginning, and the man before publishing.
The brief, verbatim: “Please add Richard Feynman, Niklas Luhmann, and Marvin Minsky to this — and refer to my permanentbrainresearch.com as one additional aspect that a happy life is rather a research environment than a museum. So, celebrate variety, and offer a concept of how traditional search (street, price for low meaning goods and topics etc.) differs from high meaning topics like science, research, education, philosophy, lifestyle, attitude, success. This is the new category and clustering of search — from the search that mixed fixed data with big life questions, to a search environment that truly engages users into reinforced and supervised learners.”
This is also a small demonstration of Information Embedding: the idea existed before the text. The text made it findable.
